FEATURES







BENEFITS






LEVERAGE TECHNOLOGY & DOMAIN


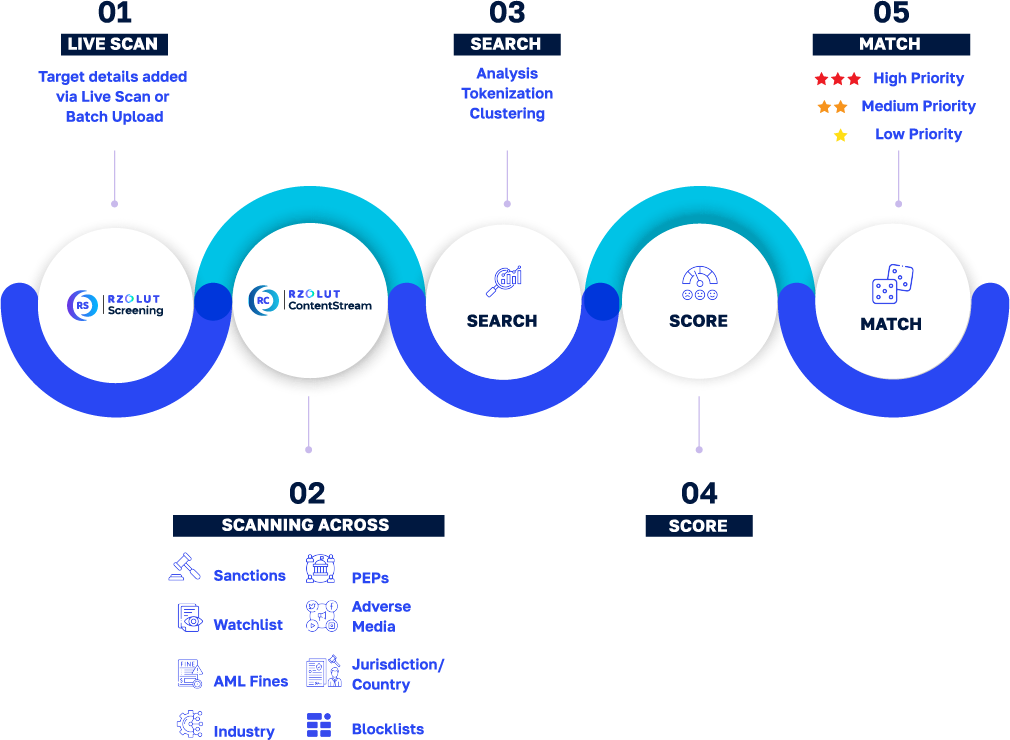
MATCHING ENGINE: PARAMETERS
- Phonetic and/or spelling differences
- Missing name components
- Rarity of a shared name component
- Initials
- Nicknames
- “Cousin” or cognate names
- Uppercase/Lowercase
- Reordered name components
- Variable Segmentation
- Corresponding name fields
- Truncation of name
RZOLUT’s name matching engine provides the capability to perform name matches, name searches, and translations across multiple languages and scripts. The natural language processing algorithms utilize machine learning (ML) and cutting-edge NLP techniques for matching.
The scores serve as a relative indication of how similar two names are, or how a search name matches a target name; the higher the score, the stronger the match. With the ability to customize the scoring engine, the product offers teams the flexibility to configure it based on risk.

contactus@rzolut.com

